In early 2026, OpenAI and Anthropic both published deep dives on Harness Engineering. OpenAI showed how 3 engineers used Codex to produce a million lines of code. Anthropic demonstrated an Initializer-Coder two-stage architecture that keeps agents working across multiple context windows. Both are excellent articles — and both focus on Coding Agents: write correct code, pass tests, merge PRs.
We use Coding Agents too. Claude Code is our primary engineering tool. But what we're building with it is a different kind of agent entirely — one that runs ad campaigns across platforms, generates creatives, manages client budgets, and coordinates data pipelines. nexad is an AI-native advertising platform. We use AI agents to build AI agents.
This creates an unusual pressure on our engineering harness. The product our Coding Agent builds has consequences that go beyond broken tests: a bad deployment can get a client's ad account suspended, burn budget on policy-violating creatives, or destroy audit trails needed for billing. The margin for error in our codebase is thinner than most — and that shapes every harness decision we've made.
Over the past three months, we tried to adopt industry harness best practices directly. Many assumptions didn't hold for a team building high-stakes agent infrastructure. This post shares the judgments we formed, the practices behind them, and the problems we still haven't solved.
1. Why Our Harness Standards Are Higher Than Usual
Before getting into how we harness our Coding Agent, it's worth explaining why we need more than the standard playbook. The answer is the product we're building.
There's useful intuition from reinforcement learning: Environment, State, Action, Reward, Policy. The agents we build — our Marketing Agents — operate in an environment with fundamentally different constraints than a Coding Agent's.
Irreversibility. A Coding Agent's failure mode is benign: code doesn't compile, tests don't pass, PRs get rejected. You can git revert and try again. The Marketing Agents we're building submit campaigns to Google Ads, spend client budgets, and publish creatives that might violate platform policies. A suspended ad account isn't fixed by changing a few lines of code. So every bug our Coding Agent introduces into the Marketing Agent codebase carries amplified risk — it's not just bad code, it's potentially bad code that spends real money.
Tension between creativity and constraints. The Marketing Agents we build must balance creative quality (compelling copy, effective targeting) against hard constraints (brand guidelines, platform policies, budget caps). This means our codebase is full of nuanced business logic — the kind of code where "technically correct" and "actually correct" diverge. A Coding Agent that doesn't understand these subtleties can produce code that passes all tests but breaks the product.
Delayed feedback. Our Marketing Agents' output quality is measured by CTR, ROAS, and conversion rates — signals that take hours or days. This means bugs in the ad-serving logic may not surface until real budget has been spent. We can't rely on fast feedback loops to catch Coding Agent mistakes; the harness has to catch them upfront.
These characteristics — irreversible downstream effects, nuanced business logic, and delayed feedback — explain why we treat harness engineering as infrastructure, not process. Every harness decision traces back to a business requirement and a deep understanding of the product context — not engineering preference or vibes brainstormed in a conference room.
2. Constraints Are Only Real When Machines Can Execute Them
This is where we burned the most time.
Early on, we wrote rules in documentation: CLAUDE.md said "use kwargs logging," "follow import hierarchy," "use soft deletes," even some team nicknames (when the agent forgot those, we knew the CLAUDE.md was losing its grip 🤣). The agent read the rules. It followed them most of the time. But it regularly forgot under pressure — especially after Claude upgraded to 1M context.
Our team spent 30–40% of its time on manual quality assurance — hand-reviewing code, manually running tests, manually checking spec compliance. This obviously doesn't scale.
We studied OpenAI's Harness blog carefully (thank you) and started encoding rules as automated checks. We built 8 custom lint scripts: check_structured_logging.py catches f-string logging; check_soft_delete.py catches direct session.delete() calls; check_api_doc_sync.py catches API changes without doc updates. These run in CI in non-blocking mode (we have to tolerate some existing violations — that's tech debt to pay down separately).
We distilled this into a constraint enforcement hierarchy:
| Level | Mechanism | Enforcement |
|---|---|---|
| 1 | CI Linter (blocks merge) | Highest |
| 2 | Pre-push Hook (blocks push) | High |
| 3 | Automated check (non-blocking, logged) | Medium |
| 4 | CLAUDE.md / docs rule | Low |
| 5 | Verbal instruction in prompt | Lowest |

From bottom to top, enforcement degrades. Now, every time we add a new rule, we ask first: can this be a linter? If yes, write the linter first, then the docs.
This aligns almost exactly with OpenAI's conclusion — "when documentation falls short, promote the rule into code" — and we arrived at it independently.
For our codebase this matters even more. check_soft_delete.py looks like a code style check, but behind it is a business requirement: hard-deleting ad account records breaks the audit trail needed for billing reconciliation. This mapping between business rules and code conventions — where a style violation is actually a business incident waiting to happen — is what makes harness engineering in our domain distinctive.
3. Self-Evaluation Fails Because of Shared Context, Not Shared Models
Anthropic proved an important finding in their Long-Running Agents paper: letting an agent evaluate its own output fails systematically. Agents mark features as complete when the actual functionality doesn't work. Their solution: separate the Generator and the Evaluator.
We formed a more precise judgment in practice: what fails isn't same-model evaluation — it's same-context evaluation.
In our review phase, after the Main Agent completes spec compliance checks (which require full context of the plan), it spawns a SubAgent for code quality review. This SubAgent uses the same model (Claude), but with completely different context: it receives only the git diff, project rule files (docs/engineering/rules/*.md), and a dedicated role definition (.claude/agents/code-reviewer.md) that frames it as a "skeptical Senior Reviewer." It knows nothing about the Main Agent's reasoning, compromises, or shortcuts.
The results were surprisingly effective. The SubAgent consistently catches cross-layer import violations, logging format errors, and missing test coverage — exactly the issues the Main Agent "rationalized away" within its own context.
This finding matters for startups. Cross-model evaluation (e.g., using OpenAI to review Claude's output) adds cost, latency, and integration complexity. Context isolation gives you roughly 90% of the benefit at a fraction of the cost. We do use cross-model review (Codex for sanity-checking plans), but for daily code quality, a context-isolated same-model SubAgent is the workhorse.

4. Harness Strictness Should Be a Variable, Not a Constant
This is the insight we think is most worth sharing.
Both OpenAI's and Anthropic's articles implicitly assume all code changes receive the same level of quality control. The entire pipeline treats every change equally. This is roughly correct for pure Coding Agents — code is either right or wrong, no middle ground.
But in real product development, a production API serving unknown users and an internal admin panel need very different levels of security review. A dev environment script and a core transaction flow need very different test coverage standards. We found that roughly 30% of agent time was wasted running unnecessarily strict checks on low-risk code.
Our solution is a Delivery Tier governance system, T0 through T3. The core logic: user controllability determines harness strictness.
| Tier | Scenario | User Profile | Control Intensity |
|---|---|---|---|
| T0 | Production core paths | Unknown/potentially hostile users | Maximum standards across all 6 dimensions |
| T1 | Client preview | Close partners with tight feedback loops | Security + observability focus |
| T2 | Internal systems | Fully controlled internal users | Basic safeguards |
| T3 | Dev / Eval | Engineering team | Minimal constraints |
Tier detection is automatic based on code paths. Our monorepo contains 14 packages: apps/web/ maps to T0, apps/admin-web/ maps to T2, scripts/ maps to T3. The agent declares a tier during the Plan phase; humans confirm or override. Every subsequent phase — Review, Test, Ship — loads the corresponding checklist automatically.
The final PR body includes a 6-dimension compliance matrix (Security, Reliability, Observability, Performance, UX, Compliance).
Anthropic proposed that "harness complexity should match model capability." We believe this can be extended further: harness strictness must match both model capability and delivery risk. Model capability is one axis; business exposure is another. Delivery Tier is the concrete implementation of the latter.
5. Progressive Disclosure Is Not an Optional Optimization — It's an Architectural Requirement
Our CLAUDE.md grew from 50 lines to 200+. The effect improved steadily, then suddenly degraded — the agent started selectively ignoring rules.
OpenAI captured this precisely: "Too much guidance becomes non-guidance. When everything is 'important,' nothing is." We independently validated this in practice.
The solution is progressive disclosure. CLAUDE.md stays at ~180 lines and serves as an entry-point index pointing to detailed rules in docs/. Each skill loads only the rule files it needs when triggered. /nex-reviewer loads import-rules.md (49 hierarchy rules) and logging-rules.md only at invocation. /nex-tester loads test-pattern-guide.md only when triggered. The agent receives specific rules only when it needs them.
This is essentially the same strategy Cursor uses for MCP tool descriptions — lazy loading instead of preloading. It's also the same lineage as Claude Code's SKILL.md mechanism. The industry is converging on the same conclusion through different paths: an agent's context is a scarce resource and needs to be managed as carefully as memory.
6. Data
Enough judgment calls — let's look at numbers. The data below comes from our git log, covering January 2026 to present. We can't share exact figures, but the trends speak for themselves.
The first dataset is weekly commit velocity. In W08, we began concentrated harness infrastructure buildout — first batch of linters deployed on Feb 12, first hook on Feb 26, then 4 hooks and 7 core skills deployed in a single day on March 2. The impact is visible in W09:
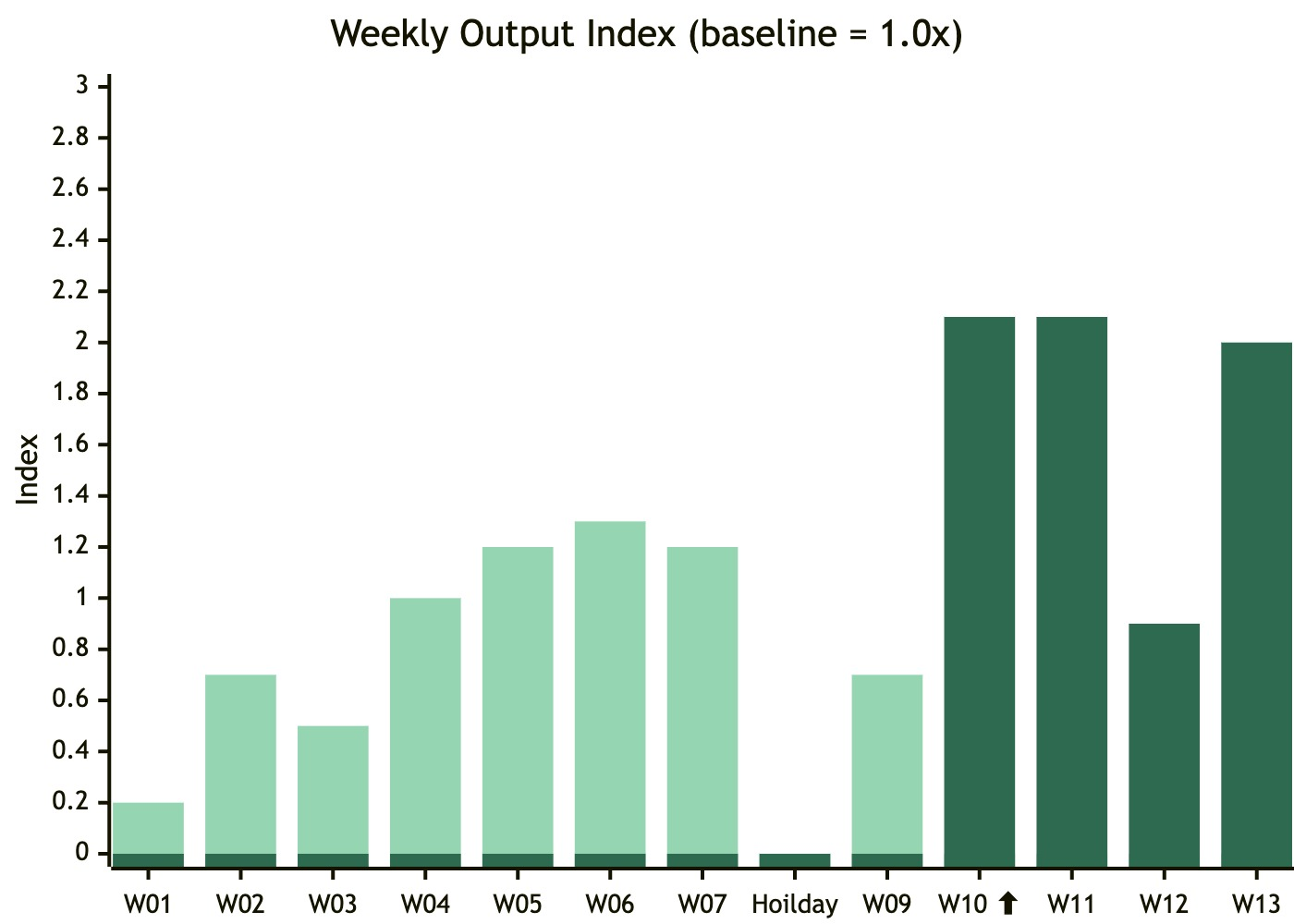
From W09 to W10, the output index jumped from 0.7x to 2.1x — nearly 3x. It has since stabilized around 2x. The acceleration mechanism isn't mysterious: the harness absorbed quality assurance work that humans previously did manually. Before deployment, we spent significant time on manual review, testing, and spec verification. Afterward, skills pipelines and hooks automated this work. The harness didn't make the agent faster — it turned humans from checkers into decision-makers.
The second dataset is commit type distribution. One notable signal: feat and fix run at nearly 1:1. This isn't coincidence — as agents rapidly produce features, they also rapidly produce issues that need fixing. This validates exactly why the harness is necessary: without automated constraints and verification, fix count scales linearly with feat count.
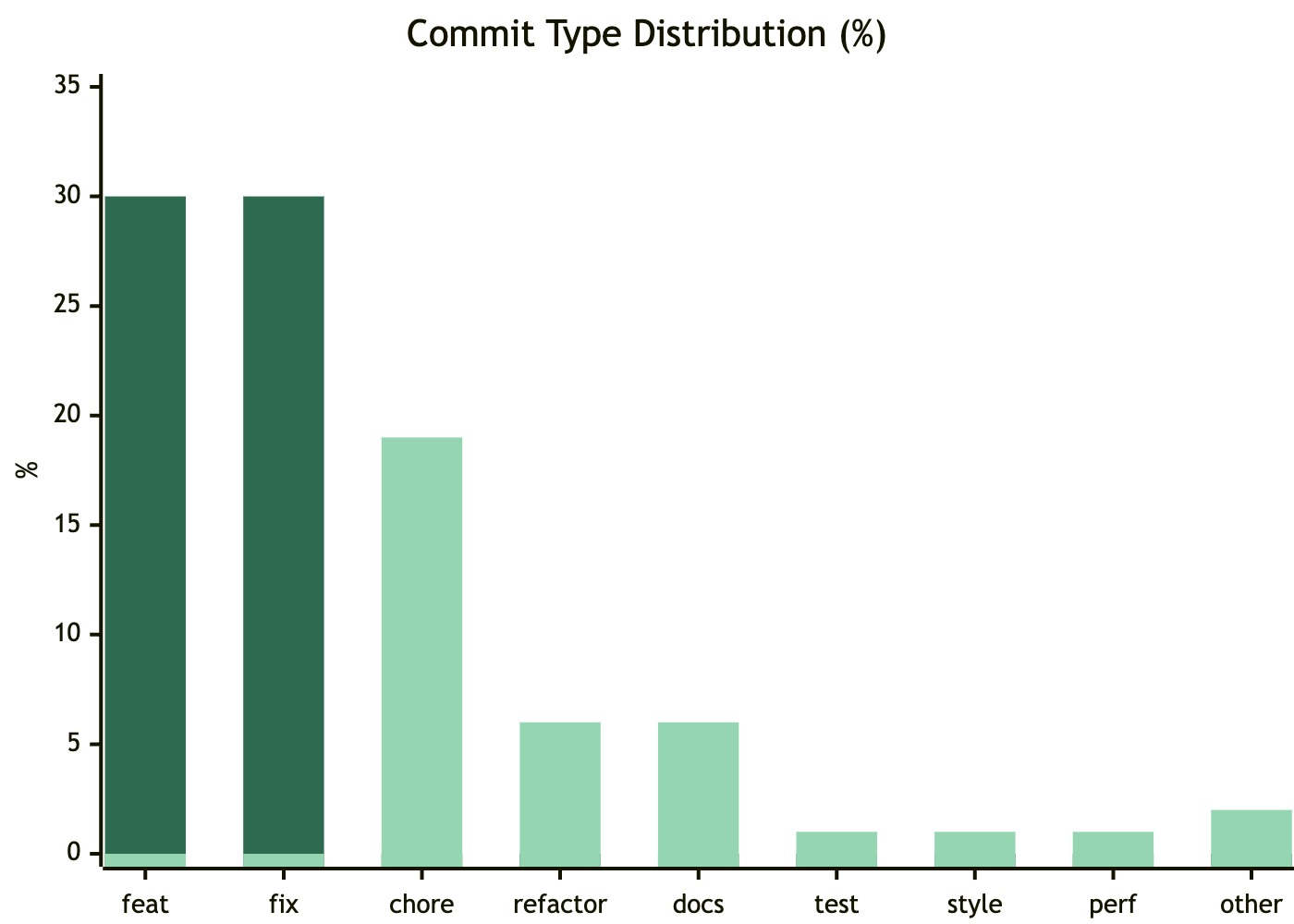
Another data point: across all ~2,000 commits, 27% involve documentation changes and 15% involve test file changes. This isn't accidental — our skill definitions make test and doc synchronization mandatory steps. Eight custom linters run at pre-push. Agent output passes through at least 2–3 automated checks before reaching the main branch.

7. Problems We Still Haven't Solved
7.1 Tech Debt Accelerates Under AI
Agents faithfully replicate patterns that already exist in the repo — including bad ones.
One incorrect logging format was introduced, and the agent continuously copied it across all new code. A human engineer would typically think "this pattern looks wrong, I shouldn't follow it," but an agent's pattern-matching mechanism biases it toward extending existing patterns. We intercept known bad patterns via linters, but we haven't yet built what OpenAI calls a "garbage collection" mechanism — an agent that periodically scans for code drift and automatically opens fix PRs. That's next on our roadmap.
7.2 The Plan-Todo-Progress Trifecta
People have asked why we maintain three-document sets (docs/process/active/{name}/{plan,todo,progress}.md). It looks like over-engineering. This system wasn't invented in a vacuum — it came from a specific failure mode: without external artifacts, the agent tries to complete complex features in one shot, exhausts its context midway, and leaves the next session to guess what happened. This matches exactly the failure mode Anthropic documented in their Long-Running Agents paper — they use claude-progress.txt and feature lists to solve it; we use the trifecta.
One critical design decision here: every Todo item must include a Verify command and Expected output — down to the exact shell command and expected string. This isn't arbitrary granularity — it lets the TaskCompleted hook mechanically verify completion status instead of trusting the agent's self-assessment.
7.3 The Last Mile of Creative Quality
Our harness can check policy compliance, brand guideline adherence, and technical correctness. But whether an ad creative will actually perform — whether the copy resonates, whether the visual stops the scroll — that's still human judgment. The gap between "policy compliant" and "high-performing creative" is where we currently can't automate.
Closing
Junyang wrote in his piece on Agentic Thinking: "The future is a shift from training models to training agents, and from training agents to training systems." Our experience partially validates this.
Over the past three months, we spent more time designing skill pipelines, debugging hook scripts, and refining the Delivery Tier matrix than we did building any single feature. But it's precisely this scaffolding that lets agent-produced code reliably serve real users every day.
Harness Engineering is just getting started. As model capabilities improve, constraints that are necessary today may become redundant tomorrow — Anthropic has observed this trend with each generation of Claude.
But one core judgment remains constant: when you're using AI agents to build AI agents, the harness isn't optional infrastructure — it's the product.
When a Coding Agent's mistake cascades through a Marketing Agent into a client's ad account, "enforce invariants, not micromanage implementations" stops being an engineering principle. It becomes a survival strategy.
The form of the reins changes. The role of the reins does not.
nexad Engineering Team · March 2026
nexad is building AI-native advertising infrastructure · nex.ad